Make a rational Network in Pytorch¶
To use Rational in Pytorch, you can import the Rational module and instantiate a rational function:
from rational.torch import Rational
rational_function = Rational() # Initialized closed to Leaky ReLU
print(rational_function)
# Pade Activation Unit (version A) of degrees (5, 4) running on cuda:0
# or Pade Activation Unit (version A) of degrees (5, 4) running on cpu
depending on CUDA available on the machine.
To place the rational function on the cpu/gpu:
rational_function.cpu()
rational_function.cuda()
To inspect the parameter of the rational function
print(rational_function.degrees)
# (5, 4)
print(rational_function.version)
# A
print(rational_function.training)
# True
If you now want to create a Pytorch Rational Network class:
import torch
import torch.nn as nn
class RationalNetwork(nn.Module):
n_features = 512
def __init__(self, input_shape, output_shape, recurrent=False, cuda=False, **kwargs):
super().__init__()
n_input = input_shape[0]
n_output = output_shape[0]
self._h1 = nn.Conv2d(n_input, 32, kernel_size=8, stride=4)
self._h2 = nn.Conv2d(32, 64, kernel_size=4, stride=2)
self._h3 = nn.Conv2d(64, 64, kernel_size=3, stride=1)
self._h4 = nn.Linear(3136, self.n_features)
self._h5 = nn.Linear(self.n_features, n_output)
nn.init.xavier_uniform_(self._h1.weight,
gain=nn.init.calculate_gain('relu'))
nn.init.xavier_uniform_(self._h2.weight,
gain=nn.init.calculate_gain('relu'))
nn.init.xavier_uniform_(self._h3.weight,
gain=nn.init.calculate_gain('relu'))
nn.init.xavier_uniform_(self._h4.weight,
gain=nn.init.calculate_gain('relu'))
nn.init.xavier_uniform_(self._h5.weight,
gain=nn.init.calculate_gain('linear'))
if recurrent:
self.act_func1 = Rational(cuda=cuda)
self.act_func2 = self.act_func1
self.act_func3 = self.act_func1
self.act_func4 = self.act_func1
else:
self.act_func1 = Rational(cuda=cuda)
self.act_func2 = Rational(cuda=cuda)
self.act_func3 = Rational(cuda=cuda)
self.act_func4 = Rational(cuda=cuda)
if cuda:
self.cuda()
def forward(self, input):
x1 = self._h1(input)
h = self.act_func1(x1)
x2 = self._h2(h)
h = self.act_func2(x2)
x3 = self._h3(h)
h = self.act_func3(x3)
x4 = self._h4(h.view(-1, 3136))
h = self.act_func4(x4)
out = self._h5(h)
return out
Now we can instanciate a Rational Network and a Recurrent Rational Networl and pass them inputs.
use_cuda = False
RN = RationalNetwork((1, 84, 84), (3,), cuda=use_cuda)
RRN = RationalNetwork((1, 84, 84), (3,), recurrent=True, cuda=use_cuda)
input = torch.rand((2, 1, 84, 84)) # Batch of 2 84x84 images (Black&White)
if use_cuda:
input = input.cuda()
output_rn = RN(input)
output_rrn = RRN(input)
print(output_rn)
# tensor([[-0.0258, -0.1401, -0.0721],
# [-0.0107, -0.0262, -0.0528]], grad_fn=<AddmmBackward>)
print(output_rrn)
# tensor([[-0.1035, 0.0773, -0.3861],
# [-0.2435, 0.1728, -0.4584]], grad_fn=<AddmmBackward>)
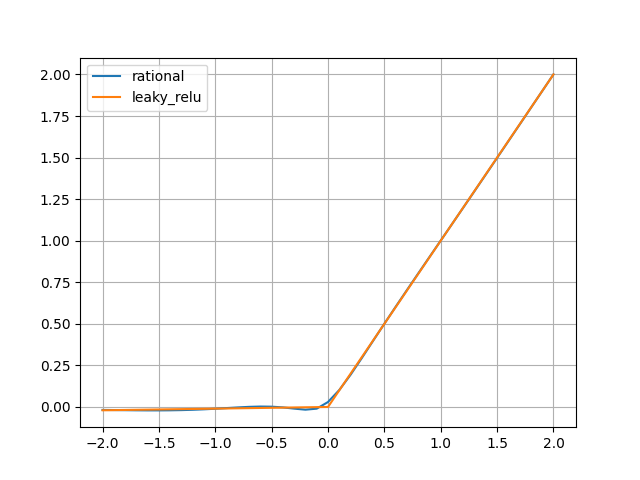
To see the activation function:
import matplotlib.pyplot as plt
input = torch.arange(-2, 2, 0.1)
rational_function.cpu()
lrelu = nn.LeakyReLU()
plt.plot(input, rational_function(input).detach(), label="rational")
plt.plot(input, lrelu(input), label="leaky_relu")
plt.legend()
plt.grid()
plt.show()